After an episode with introductory information about the platform, today we present Apache Kafka from a practical perspective.

Kafka basics
Before you get to know Apache Kafka in-depth, you need to understand key terms such as themes, brokers, producers, and consumers. Below we explain detailed descriptions of key terms and components.
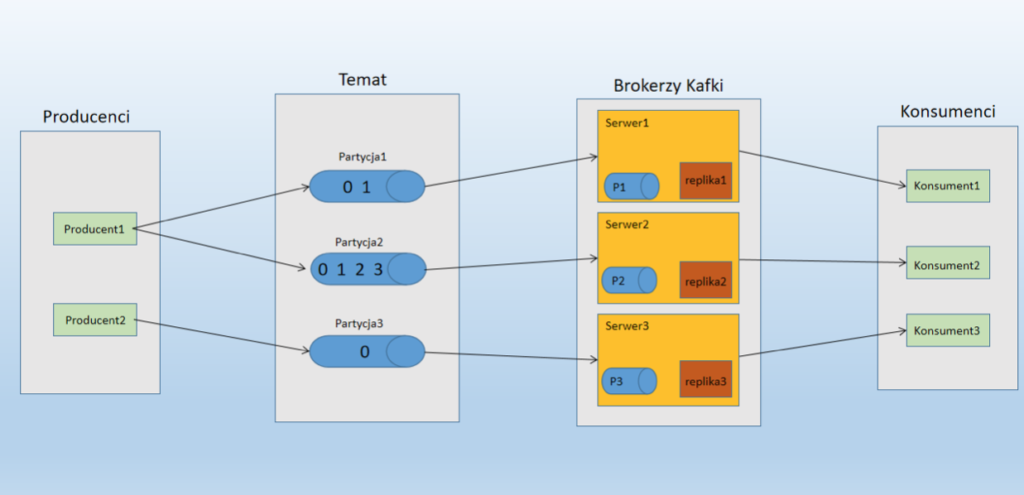
Topic configured with three partitionsIn the diagram above, a topic (topic) is configured with three partitions. Partition 1 has two offset coefficients 0 and 1. Partition 2 (partition 2) has four offset coefficients 0, 1, 2, and 3, and partition 3 (partition 3) has one offset coefficient 0. The ID of the replica is the same as the ID of the server on which it is hosted.
Assume that if the replication factor for this topic is set to 3, Kafka will create three identical replicas for each partition and place them in the cluster to make them available for all its operations. To balance the load in the cluster, each broker stores at least one of these partitions. Multiple producers and consumers can publish and retrieve messages simultaneously.
Topics
Message flows that belong to a specific category are called Topics. The data is stored in Topics. Topics are divided into sections. For each Topic, Kafka maintains a minimum range of partitions. Each such partition contains messages in an immutable order. A partition is implemented as a set of segmented files of equal size.
Partition
A topic can have multiple partitions, so it can handle any amount of data.
Partition offset
Each partition message has a unique sequence identifier called an offset.
Partition replicas
Replicas are just backup copies of partitions. Replicas never read or write data. They are used to prevent data loss.
Brokers
These are simple systems responsible for maintaining published data. Each broker can have zero or more partitions per topic. Hypothetically, if there are N partitions in a topic and N brokers, there is one partition per broker.
- Assuming there are N partitions in the topic and more than N brokers (n+m), then the first N brokers will have one partition and the next M brokers will have no partitions for that particular topic.
- Assuming the topic has N partitions and M brokers (N > M), then each broker will have one or more partitions to share. This is not recommended due to uneven load distribution among brokers.
Apache Kafka Cluster
Kafka clusters can be scaled without downtime. These clusters are used to manage the persistence and replication of message data.
Producers
Producers are publishers of one or more Apache Kafka topics and send data to Kafka brokers. Each time a producer publishes a message to a broker, the broker simply appends the message to the last segment file. As a result, the message will be appended to the partition. Producers can also send messages to partitions of their choice.
Consumers
Consumers read data from brokers, subscribe to one or more topics and consume published messages by retrieving data from brokers.
Leader
The leader is the node responsible for reading and writing all partitions. Each partition has one server that acts as the leader.
There was a theory, now some practice
Installing Kafka
To set up an Kafka cluster, in this example we will use the Docker containerization tool
https://docs.docker.com/get-docker/
and Docker Compose
https://docs.docker.com/get-started/08_using_compose/
Zookerer listens on port 2181 for Kafka, which is defined in the same place. Kafka is hosted on host 39092.
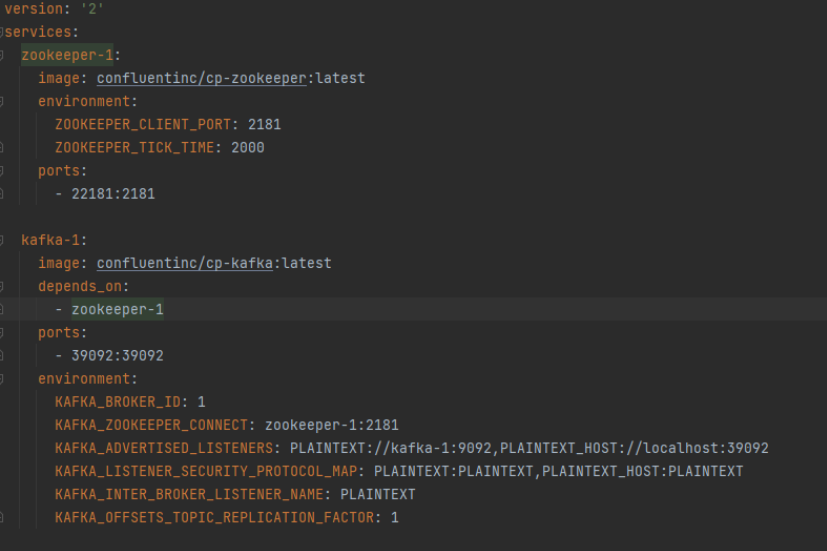
Start the server using the docker-compose command
$ docker-compose up -d
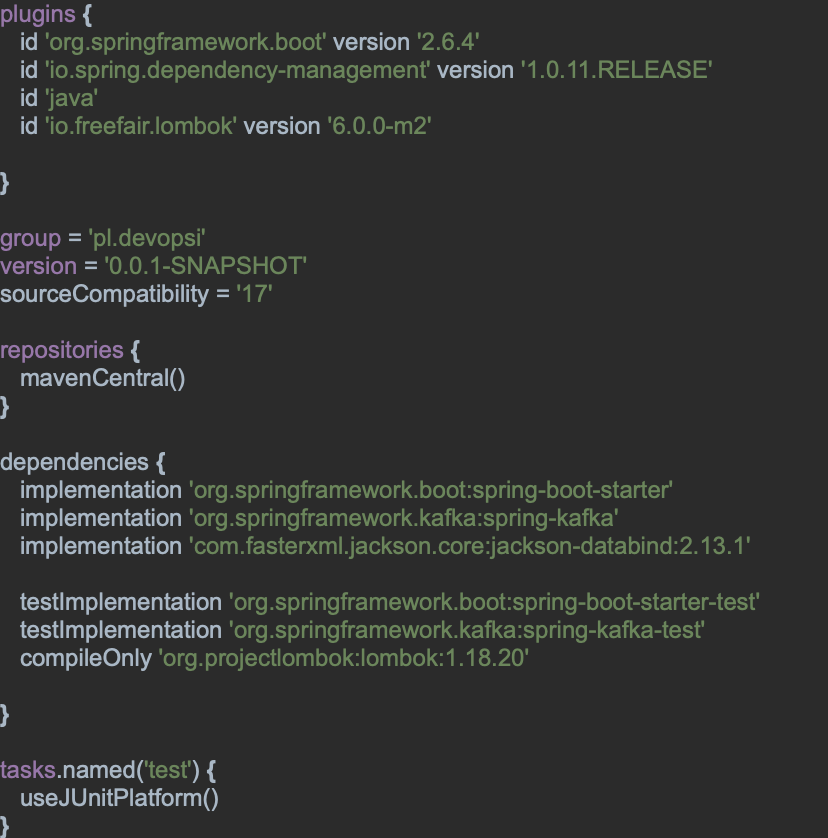
Once we have our Kafka cluster, we can start implementing the client, it will be implemented in java with the help of Spring-Kafka. All the dependencies are placed in Gradle.
build.Gradle
application.properties:

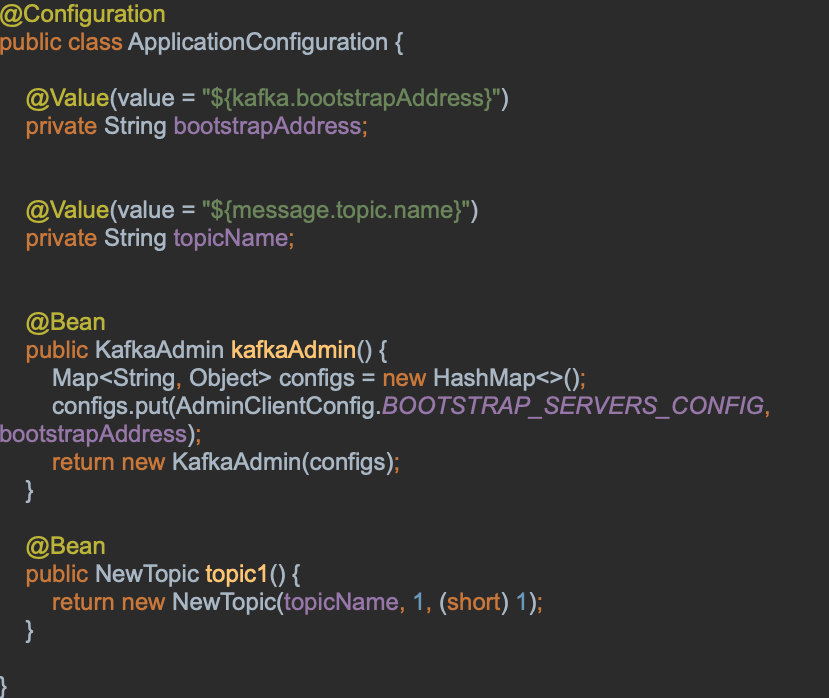
Application configuration:
– Create Kafka admin
– Creation of a Topic
Manufacturer configuration

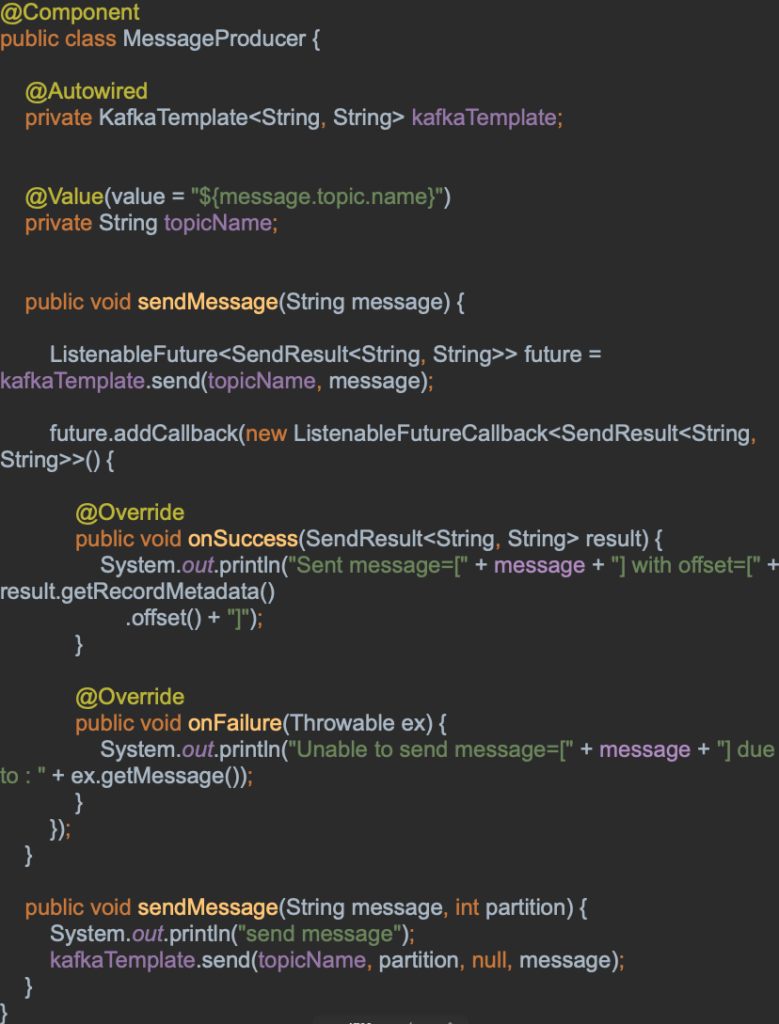
MessageProducer
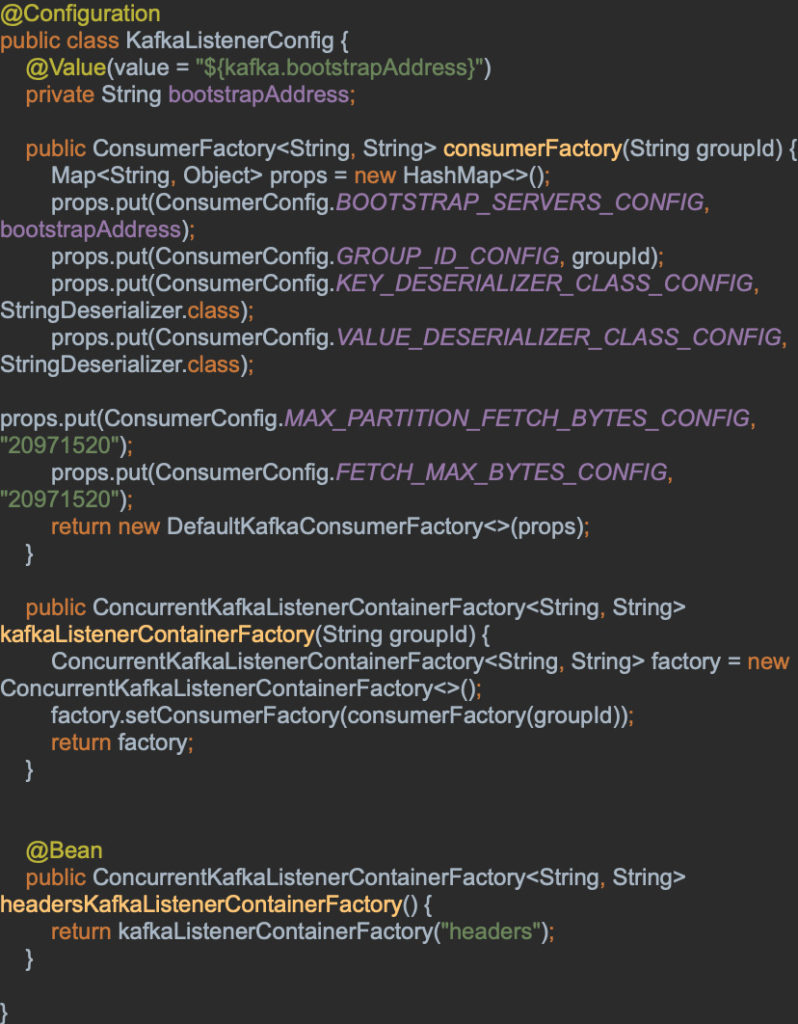
KafkaListenerConfig
MessageListener

Application code and example invocation of producer and listener

After running, the following result should appear
