
As we can read at official Hazelcast site (www.hazelcast.com) Hazelcast is a streaming and memory-first application platform for fast, stateful, data-intensive workloads on-premises, at the edge or as a fully managed cloud service. In this tutorial I will focus on simple usage and basic configuration Hazelcast Client with Java and Spring to show how to cache data in memory to avoid selecting data from database that are immutable, but must be downloaded each time the REST service is called.
Prerequisites of our task
- Java SDK 8+ (17 recommended)
- IDE (IntelliJ recommended)
- Postman (to send REST requests to our RESTful application)
Hazelcast – tutorial coverage

Hazelcast provides application scaling by providing access to frequently used in-memory data and an elastically scalable data grid.If you will download source code from link in the section below, you will learn much more than only basic Hazelcast configuration:
- HOWTO create simple RESTful Spring Boot application with PUT, GET and POST HTTP methods
- HOWTO write Unit and Integration tests (H2 database) with Spock and Groovy
- HOWTO handle exceptions using @ControllerAdvice annotation combines with @ExceptionHandler
- HOWTO work with Postman collections
Problem to solve in theory
Imagine we have an application whose task is to provide services that allow you to add, update and download data about users and their list of antiallergic drugs. Theoretically, our application is used by pharmaceutical systems in many countries and our services are used in billions of requests per hour. What is noteworthy here is that the drug list for each user is unchanging. What is important to us here is the optimization of the cost of searching user data in database. Data such as first name, last name must be downloaded every time and we cannot cache them. However, we can use Hazelcast to keep the data about the drug list for each user in the memory. Thanks to this, we will not have to query the database every time.

So let’s code!
Source code of this tutorial can be found in https://github.com/piotrjucha/hazelcast-tutorial. You can easily download the code, compile and run. There is also example Postman collection to try it out for yourself.
First of all we need to set up our Spring Boot application and add required dependencies. Let’s look at this Gradle build file. Only 2 implementations for Hazelcast are needed:
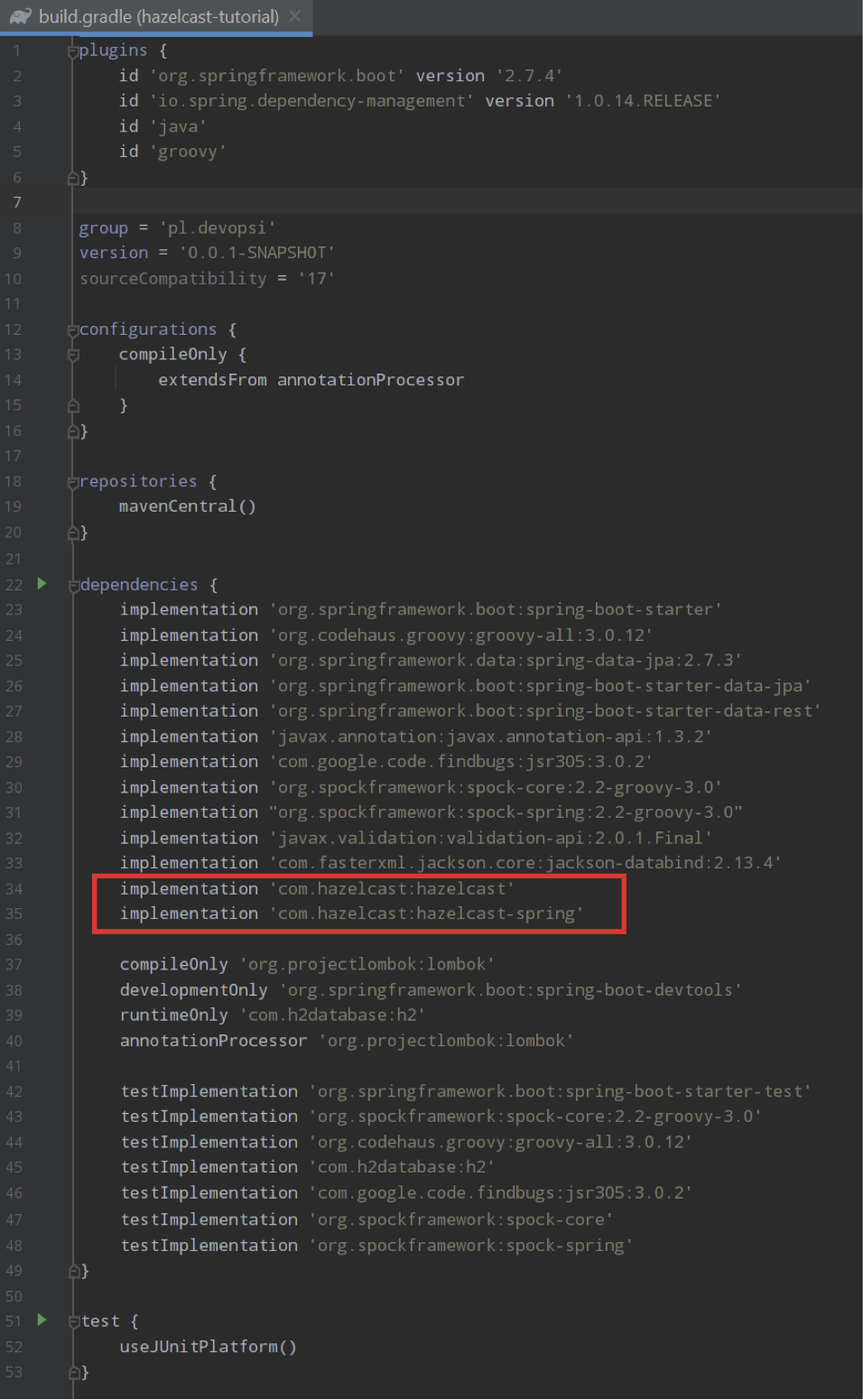
In this tutorial we will be using H2 in memory database so as not to have to install an external database. Let’s look at our base entities:
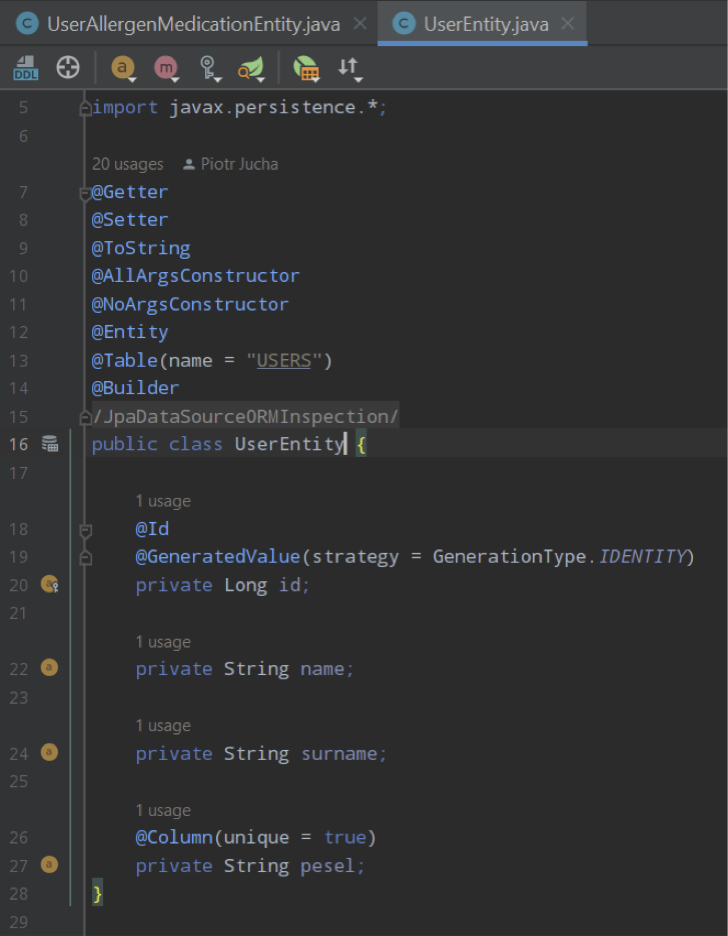
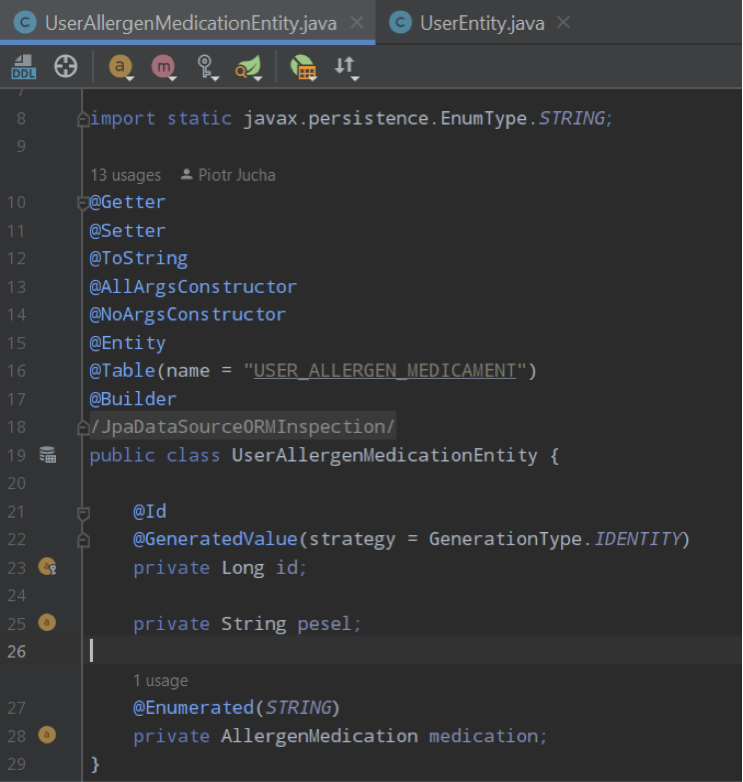
We create 2 entities
UserEntity represents user basic data like name, surname and pesel (which is unique per user) and UserAllergenMedicationEntity which represents single medication for given user’s pesel. Specially I didn’t combine User with it’s medication as a @OneToMany relation. If I do that, it would be selecting medications from database each request and that is exactly what I want to avoid here.
Having Entities implemented next step is to implement Repositories for them:
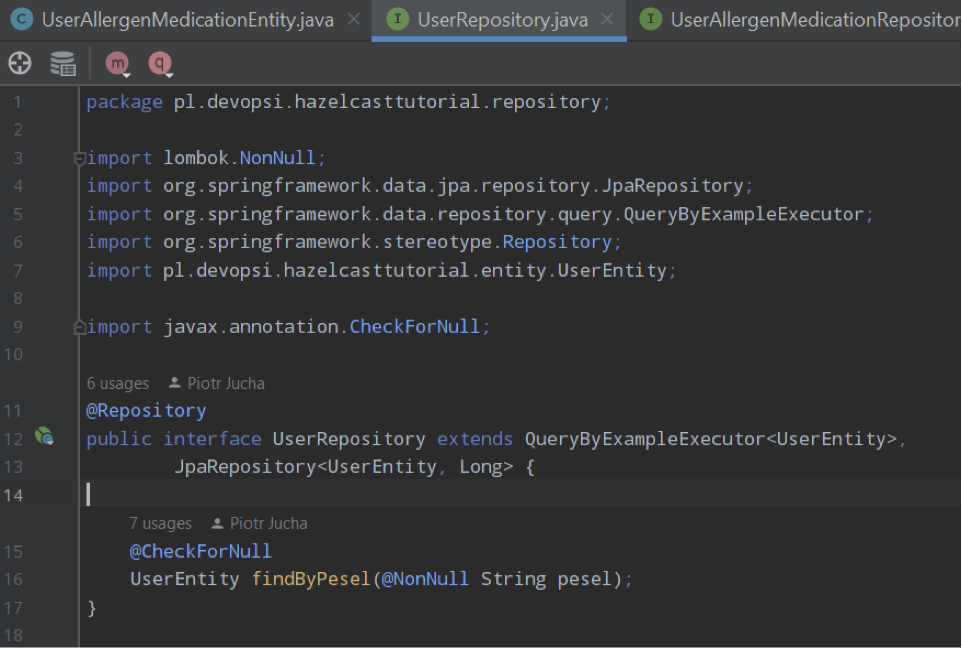
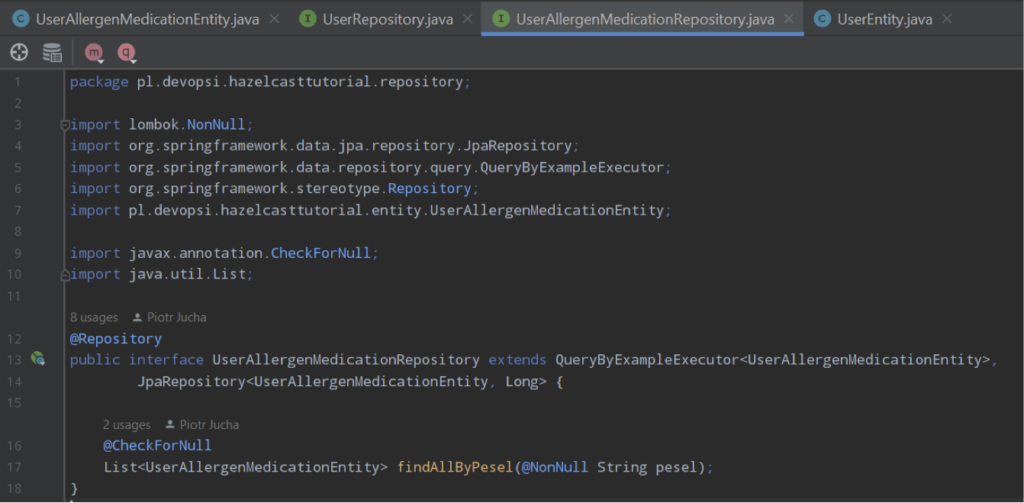
So now we have mechanism to select, save and update data using Spring Data Framwork.
We have to configure our H2 database. We create application.yml file in the root of our project and fill it with code as below:
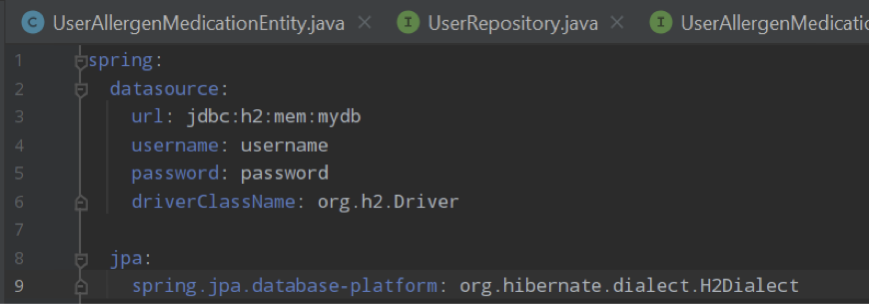
Until now we have configured database, entities, repositories and all the required dependencies for our project. We can create now some Controller to server add/update/get services for our users:
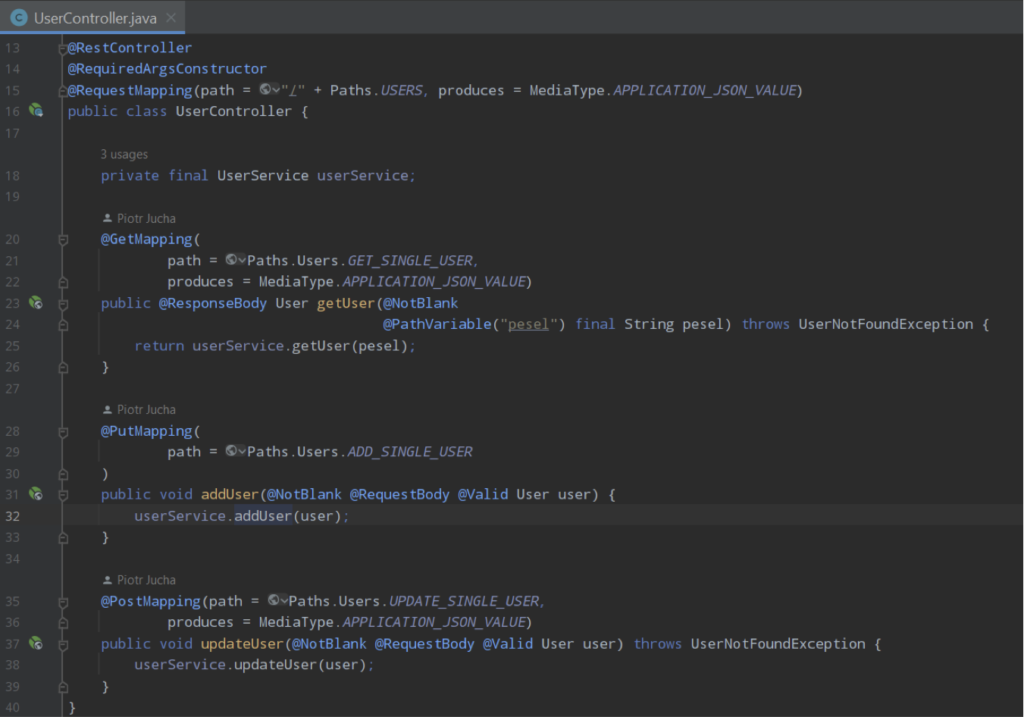
Here is the place,
Where magic begin
We will implement UserService, which will be responsible for handling logic for our controller.
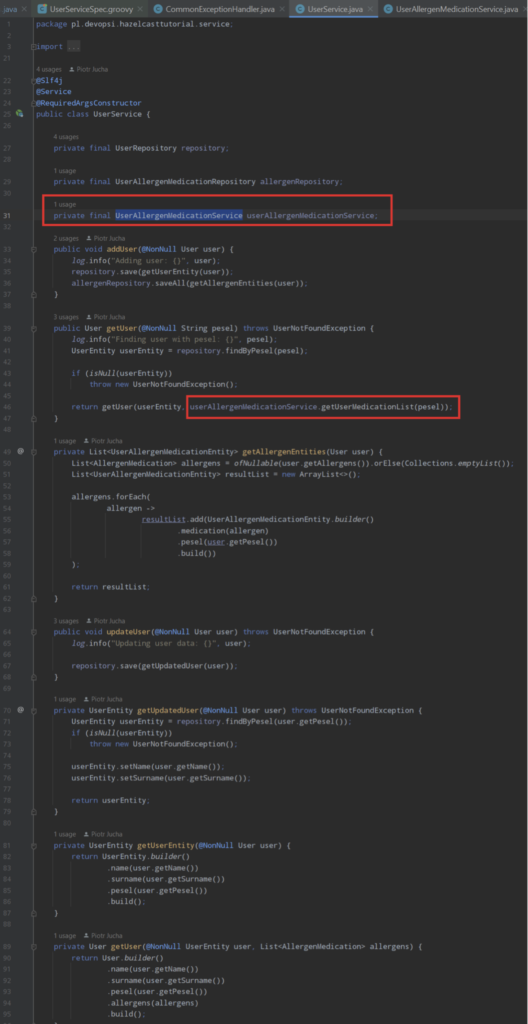
This service looks very normal and very simple. It handles basic operations. What is interesting here is UserAllergenMedicationService and the invocation of method .getUserMedicationList(pesel). It’s interesting, because inside of this method and in it’s service we have hidden the whole implementation of Hazelcast. So, let’s figure out how it works inside.
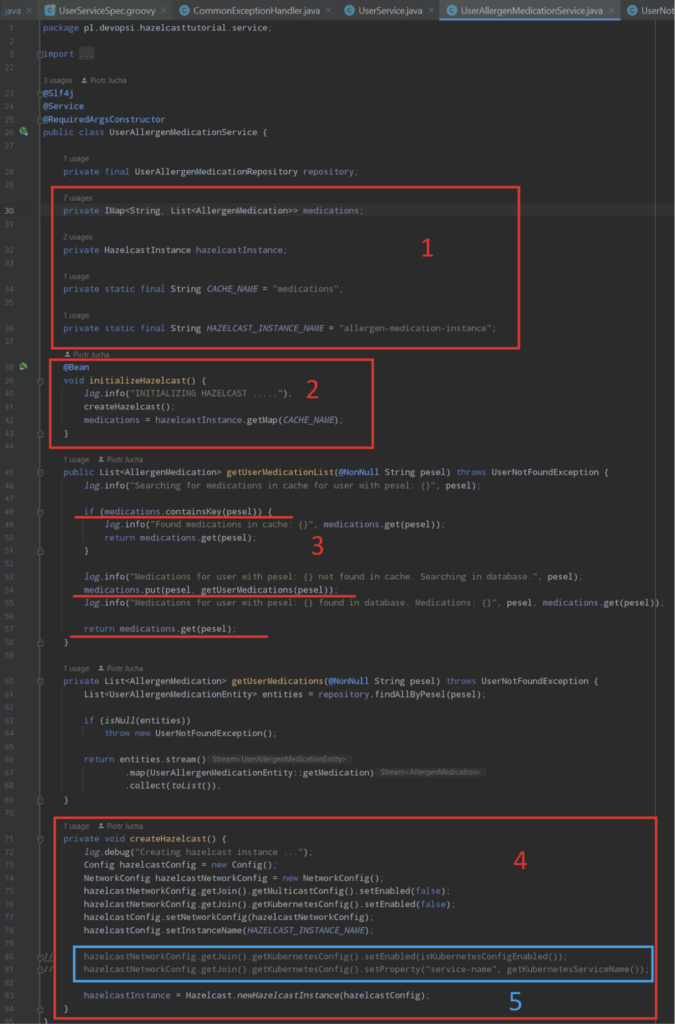
Let’s explain particular code blocks:
Part one:
- medications is special Hazelcast’s implementation of Map interface. It’s called IMap. There are many different kinds of data structures in Hazelcast we can use, but I will not explain each one. If you are interested in, go to official docs.
- hazelcastInstance is as you can guess it is an instance of Hazelcast that will be implemented in memory when the application is started and will stay in it until exiting it. (Well …. almost. I’ll explain it later.)
- CACHE_NAME is the name of our cache storage for our medications. For example if we have to have the second or more data structures for other data, we can easily create a new one with different name. We will be retrieving data just after the name of the cache.
- HAZELCAST_INSTANCE_NAME is nothing more than a global name of our instance.
Part two:
This is the place where we create Bean for Hazelcast in memory and initialize IMap. Method getMap() creates automatically new IMap for us.
Thirt part:
Here is the most interesting piece of code. Let’s look on it:
- Here we check if our map contains data. In simple words if we obtained data from database before. If yes, we simply return data.
- If not, we search for data in database, update map and return data. For the every next request of data for this unique pesel (User) we will be returning data always from cache avoiding selecting them from database.
Fourth part:
The last part of this tutorial is here. We create Hazelcast config and instance.
Fifth part:
As I said before I will explain now something very interesting about this configuration. If we also fill the configurations for Kubernetes (enabling it and setting k8s service name for this application) after deploying it on k8s it will be deployed as a separate service. Benefit of this kind of configuration is huge. After each redeploying of our application in k8s, Hazelcast will still contain data from previous version. So we avoid with this something which is called cold start in java.
Let’s try it out!
Via Postman collection included in source code under collection folder in root of the project I will add some User and try to get his data 2 times to show how it works in practice.
Here are the logs:
Adding user:
Adding user: User(name=Andrej, surname=Wars, pesel=123457124, allergens=[ACARIZAX, ACATAR, ACATARICK {………}
Getting user data for the first time: (we can see, there were no data in cache, so it has to be selected from database)
Finding user with pesel: 123457124
Searching for medications in cache for user with pesel: 123457124
[192.168.1.103]:5701 [dev] [5.1.3] Initializing cluster partition table arrangement…
Medications for user with pesel: 123457124 not found in cache. Searching in database.
Medications for user with pesel: 123457124 found in database. Medications: [ACARIZAX, ACATAR, {………}
Getting user data for the second time. We can see, for the second time data has been fetched from the Hazelcast cache:
Finding user with pesel: 123457124
Searching for medications in cache for user with pesel: 123457124
Found medications in cache: [ACARIZAX, ACATAR, ACATARICK, ADABLIX, AERINAZE, {………}